UPack PE 헤더 상세 분석

UPack으로 실행 압축 된 notepad.exe를 PEView로 확인해 보니, IMAGE_OPTIONAL_HEADER와 IMAGE_SECTION_HEADER등의 PE 구조를 제대로 인식하지 못한다.
또한 DOS Header 영역에 Import하는 DLL 파일이 보이고, DOS Stub이 보이지 않는 등 원본의 notepad.exe와는 다른 모습을 보인다.
이렇듯 PEView로 분석하는 데 어려움이 있으니 Stud_PE로 분석하자.

e_magic이 4A5D, e_lfanew는 10이다. 즉, DOS Header에 NT Header를 겹쳐서 썼다는 것이다.
그러므로 offset 10에 NT Header의 시작인 Signature 값이 보인다.
여기서 주목해야 할 요소는 SizeOfOptionalHeader의 값이다.


원본 notepad.exe는 SizeOfOptionalHeader의 값이 E0인데 UPack으로 실행 압축하고 난 뒤의 값은 148로 더 커졌다.
값이 커진 만큼 IMAGE_OPTIONAL_HEADER의 크기가 커졌고, Section Header의 시작 오프셋이 더 뒤로 밀리게 된다.
따라서 Section Header는 148 + 28(Optional Header의 시작 offset) = 170 즉, offset 170부터 시작한다.
이렇게 되면 Optional Header와 Section Header 사이에 공간이 확보된다.
여기서 한가지 더 주목해야 할 점이 있는데, 바로 NumberOfRvaAndSizes 값이다.
위 그림을 보면 해당 값이 A로 설정되어 있다. 원래 이 값은 10(h)인데 A로 설정 했다는 것은 뒤에 있는 6개의 멤버를 무시하고 그 공간을 다른 용도로 위해 확보한 것이다.
결국 무시당한 멤버를 고려한 Optional Header 영역은 아래와 같다.
위에서 확보한 공간들은 UPack의 디코딩 코드를 추가하는데 사용된다. 확보한 영역을 HxD로 확인해보자.

이렇게 보니 어떤 코드인지 알아보기 어렵다. 디버거로 확인해보자.
디버거에 이 파일을 올리면 Bad or unknown format of 32-bit executable file 이라는 에러 메시지 박스가 뜨는데 이는 NumberOfRvaAndSizes 값이 10(h)이 아니기 때문에 발생한다. 크리티컬한 에러는 아니므로 무시해도 좋다.

위와 같은 명령은 UPack에서 사용하는 코드이므로 헤더 정보라고 인식하면 오류가 발생한다.
이제 섹션에 대해서 알아볼 차례이다.

섹션의 개수는 3개이다. 위에서 구한 섹션 헤더의 시작 위치는 170이라는 것을 알았으니 해당 영역을 확인해 보자

두 번째 섹션 헤더의 offset to relocations는 원본 notepad.exe의 EP이다. 0100739D 값이 이에 해당된다.

이 파일의 섹션 정보이다. 첫 번째 섹션의 파일 offset(RawOffset)은 10이다. 이 곳은 헤더의 영역인데 UPack에서는 첫 번째 섹션의 시작이다. 즉, 헤더와 섹션을 겹쳐서 사용한다는 것이다.
그리고 첫 번째 섹션과 세 번째 섹션의 RawOffset과 RawSize가 완전히 같다. 이는 파일에서 두 섹션이 겹쳐져 있다는 것이다. 하지만 VirtualOffset과 VirtualSize의 값을 확인해 보면 메모리에는 각각 다른 영역에 로딩된다는 것이다.
즉, 파일 상태에서는 첫 번째 섹션과 세 번째 섹션이 겹쳐있고, 그 다음에 두 번째 섹션이 존재한다. 하지만, 메모리에서는 각자 다른 영역에 로딩된다.
또한 첫 번째와 세 번째 섹션 영역의 크기는 두 번째 섹션에 비하면 상당히 작다. 이는 두 번째 섹션에 원본 notepad.exe가 통째로 압축되어 있기 때문이다.
첫 번째 섹션의 VirtualSize로 미루어보아 두 번째 섹션 영역에 압축되어 있던 파일이 메모리에 로딩되면 첫 번째 섹션에 압축을 해제한다.
정리해보자면, 두 번째 섹션 영역에 압축된 notepad가 들어있고, 메모리에 올라와서 압축이 풀리면 첫 번째 섹션 영역에 풀린다.
UPack은 RVA to RAW에도 신경쓸 요소가 있다.
우선 우리가 알던 방식으로 EP의 Offset을 계산해 보자.

RVA 1018이 EP이다. 위에 첨부한 섹션 정보와 비교해가면서 보도록 하자.
공식에 대입하면 1018 - 1000 + 10 = 28 이다. 이 값이 맞는지 확인하자.

EP의 RAW를 계산한 것이니 코드가 등장할 것이라고 생각했지만, LoadLibraryA와 ordinal 정보의 영역이 등장했다.
이런 UPack의 트릭 때문에 많은 PE 유틸이 RVA to RAW에 어려움을 겪었다.
그렇다면 진짜 RAW를 구하기 위해서는 어떻게 해야 할까?
바로 첫 번째 섹션의 PointerToRawData 값은 FIleAlignment의 배수가 되어야한다는 PE스펙 규칙에서 해답을 찾을 수 있다.

즉, PointerToRawData는 200의 배수가 되어야 한다. PE 로더는 첫 번째 섹션의 PointerToRawData가 10이므로 강제로 배수에 맞춰서 인식한다. 이 경우에는 0으로 인식한다.
그렇다면 이 사실을 고려하여 계산해보자.
RAW = 1018 - 1000 + 0 = 18 이므로 아래와 같은 명령어가 나오게 된다.

UPack은 Import Table 역시 특이하게 구성되어 있다.

앞의 4바이트는 Import Table의 주소이고, 뒤의 4바이트는 Import Table의 Size이다.
주소는 RVA이므로 RAW로 변환한다. 271EE는 세 번째 섹션 영역이므로
271EE - 27000 + 0 = 1EE이다.

PE 스펙에 따르면 Import Table은 IMAGE_IMPORT_DESCRIPTOR 구조체 배열로 이루어지고 NULL 구조체로 끝나야 한다.
하지만 위 그림을 보면 진하게 표시된 부분까지가 첫 번째 구조체이고, 그 뒤는 NULL 구조체도 아니고 두 번째 구조체도 아니다. 이렇게 되면 PE 스펙에 어긋난다.
하지만 Offset 200 부터는 세 번째 섹션 메모리에 매핑되지 않는다. 그렇게 되면 200 부터는 메모리 상에서 NULL로 채워진다.

10271FF까지만 매핑이 되고, 그 뒤는 NULL로 채워졌다. 그렇게 되면 NULL 구조체로 인식이 되므로 PE 스펙에 어긋나지 않게 된다.
| offset | member | RVA |
| 1EE | OriginalFirstThunk(INT) | 0 |
| 1FA | Name | 2 |
| 1FE | FirstThunk(IAT) | 11E8 |
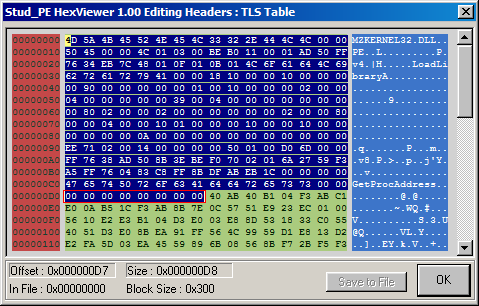
헤더 영역에서는 RVA와 RAW가 같으므로 바로 Name을 찾아가보자.

DOS 헤더에서 사용되지 않는 영역에 KERNEL32.DLL 이라는 Import DLL 이름을 써놓았다.
이제 어떤 API를 Import 하는지 살펴보자.
OriginalFirstThunk가 0이므로 FirstThunk를 따라가도 상관 없다. 둘 중 하나에만 API 이름 문자열이 나타나면 되기 떄문이다. 11E8도 RVA이므로 11E8 - 1000 + 0 = 1E8에 있을 것이다.

RVA 28과 BE에 있는 API를 Import 한다.


LoadLibraryA와 GetProcAddress를 Import 한다. 이 두 함수는 원본 파일의 IAT를 구성할 때 편리하므로 일반적인 패커에서도 많이 Import 해서 사용한다.